
graphs added to README.md
Showing
- README.md 104 additions, 2 deletionsREADME.md
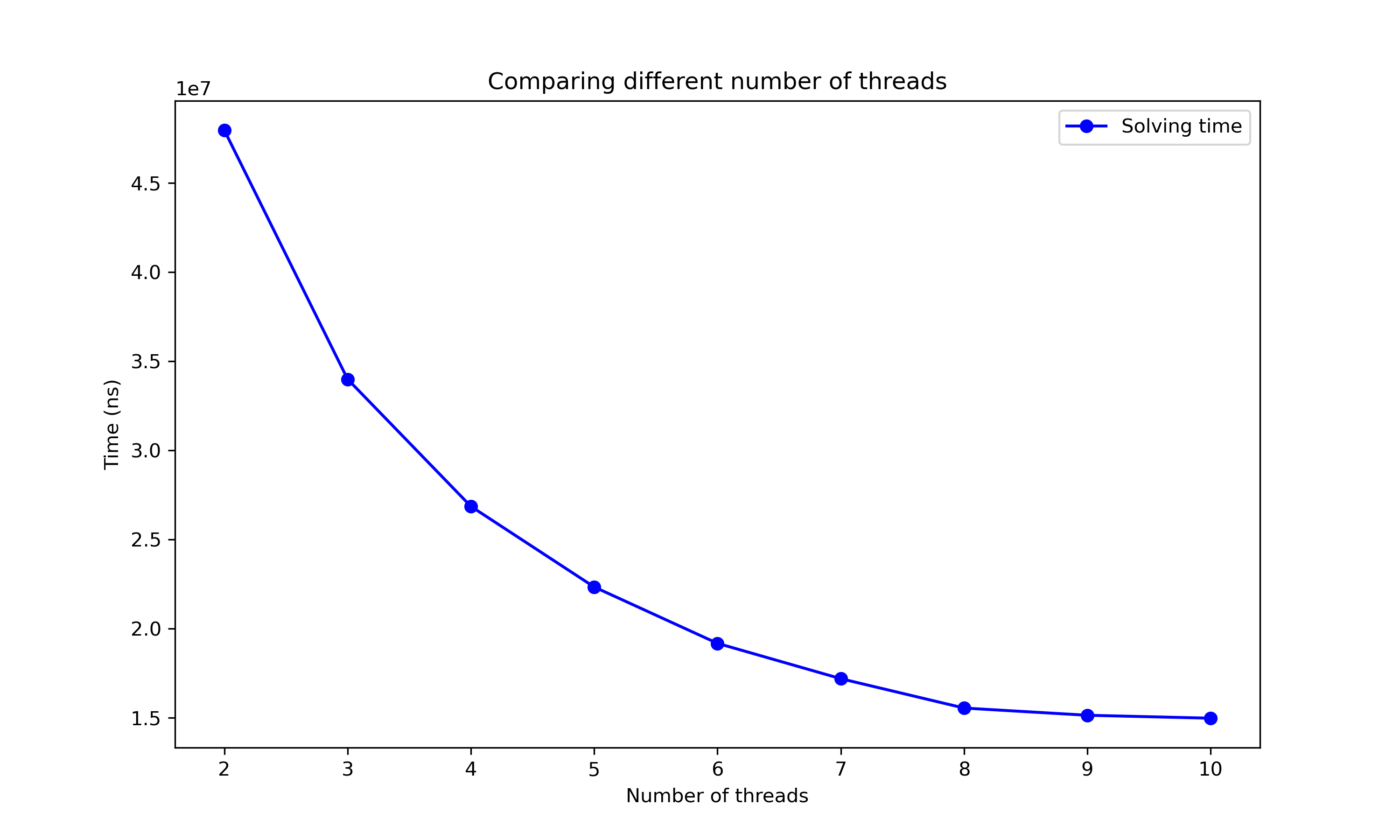
- data_analysis/algorithm_speedup_across_thread_counts.png 0 additions, 0 deletionsdata_analysis/algorithm_speedup_across_thread_counts.png
- data_analysis/brute_force_vs_branch_bound.png 0 additions, 0 deletionsdata_analysis/brute_force_vs_branch_bound.png
- data_analysis/solver_comparision.ipynb 530 additions, 197 deletionsdata_analysis/solver_comparision.ipynb
- data_analysis/synchronized_vs_parallel_bb.png 0 additions, 0 deletionsdata_analysis/synchronized_vs_parallel_bb.png
- files/stats_main.cpp 23 additions, 4 deletionsfiles/stats_main.cpp
{kind=link}
{kind=link}

| W: | H:
| W: | H:
{kind=link}
{kind=link}

| W: | H:

| W: | H:
source diff could not be displayed: it is too large. Options to address this: view the blob.
{kind=link}
{kind=link}

| W: | H:

| W: | H: